到目前为止,Hadoop已经开发了10多年,并且该版本已经更新和迭代了无数次。当前,行业中的每个人都将Hadoop的主要版本分为Hadoop1.0,Hadoop2.0和Hadoop3.0三个版本。
1. Hadoop简介首次发布Hadoop版本时,它要解决两个问题:一个是如何存储海量数据,另一个是如何计算海量数据。 Hadoop的核心设计是HDFS和Mapreduce。
HDFS解决了如何存储海量数据的问题,而Mapreduce解决了如何计算海量数据的问题。 HDFS的全名:HadoopDistributedFileSystem。
2.分布式文件系统Picture HDFS实际上可以理解为分布式文件系统。如图1所示,假设每台服务器都有自己的文件系统,那么这四台服务器是否有自己的文件系统可以存储数据。
存储空间存储10G数据。假设数据量较小,则可以存储10G数据。
当数据量大于服务器的存储空间时,单个服务器是否无法存储数据?我们可以在服务器中部署Hadoop以便构建集群(超级计算机)吗?这样,存储了4 * 10 = 40G的数据,因此当我们面对用户时,是否只有一台相当于分布式文件系统的超大型计算机? HDFS是一种主从架构,主节点只有一个NemeNode。该节点中有多个DataNode。
3. HDFS架构图假设我们这里有5台服务器,并且每台服务器都部署在Hadoop上,我们随机选择一台服务器来部署NameNode,其余服务器来部署DataNode。客户端上载文件时,假设文件大小为129M。
HDFS的默认拆分大小为128M。此时,将生成2个blkNameNodes来通知DataNode上载文件(这里有某种策略),我们假设这些文件分别存储在4个服务器上。
为什么我们需要分别存储它们?假设DataNode服务器突然停运一天。我们是否仍可以通过DataNode4或2和3读取数据,以防止数据丢失? NameNode管理元数据信息(文件目录树):文件与块,块和DataNode主机之间的关系NameNode是为了快速响应用户操作,因此将元数据信息加载到内存中,DataNode存储数据,而上传的数据为分成固定大小的文件在Hadoop 2.73之前,块在64M之后更改为128M。
为了确保数据安全性,每个文件默认为三个副本。 SecondaryNamenode会定期从NameNode节点提取Edtis和fsimage文件,并将这两个文件添加到中。
然后将内存添加到内存中,以合并这两个文件以生成新的fsimage并将其发送到NameNode。 4. HDFS写入数据过程客户端将向文件节点发送写入请求和文件路径,并通过RPC与NameNode建立通信。
NameNode检查目标文件并返回是否可以上传。客户端请求将第一个块传输到哪个DataNode服务器; NameNode根据副本数和副本放置策略分配节点,并返回到DataNode节点,例如:A,B,CClient请求节点A建立管道,A收到请求后将继续调用B,然后B将调用C建立整个管道。
完成后,该消息将逐级返回到客户端。客户端收到A返回的消息后,客户端开始将第一个块块上传到A。
该块块分为64K数据包,并在pepiline管道中从A到B连续传输,从B到C复制存储空间。块块的传输完成后,客户端再次请求NameNode上载第二块块的存储节点,并保持往复存储。
所有块块的传输完成后,客户端将调用FSDataOutputSteam的close方法以关闭输出流。调用FileSystem的完整方法来通知NameNode数据已成功写入。
5. HDFS读取数据的过程。客户端将首先向具有读取路径的NameNode发送读取请求,通过RPC与NameNode建立通信,然后NameNode检查目标文件以确定所请求的文件。
视具体情况而定,块块NameNode的位置信息将返回文件的部分或全部块块列表。对于每个块块,NameNode将返回包含该块副本的DataNode地址。
这些返回的DataNode地址将根据群集拓扑进行计算。然后按照两个规则对客户端的距离进行排序:在网络拓扑中最接近客户端的位置排名第一;心跳机制中超时机制报告的DN状态为STALE,排名较低;客户选择。







公司: 深圳市捷比信实业有限公司
电话: 0755-29796190
邮箱: momo@jepsun.com
产品经理: 聂经理
QQ: 2215069954
地址: 深圳市宝安区翻身路富源大厦1栋7楼

更多资讯
获取最新公司新闻和行业资料。
- 金属膜电阻读取技术:从信号采集到数据处理全流程详解 金属膜电阻读取的核心流程在现代电子系统中,金属膜电阻不仅是基础元件,更是实现精准电流/电压检测的关键组件。其读取过程涉及信号采集、放大、滤波与数字化处理等多个环节。1. 信号采集阶段通过将金属膜电阻串联于主...
- 如何正确解读WAN2012H245C04和WAN2012F245H04数据手册中的技术参数? 深入理解数据手册:从参数到实际应用对于工程师和采购人员而言,准确理解WAN2012H245C04与WAN2012F245H04的数据手册内容至关重要。本文将帮助您快速掌握关键信息,避免选型失误。1. 封装与引脚定义解析两款器件均采用 SMD(表面贴...
- 深入解读光颉viking CL-S系列电感器的技术参数与选型指南 光颉viking CL-S系列电感器技术详解与实用选型建议面对市场上众多电感器型号,如何准确选择适合项目需求的光颉viking CL-S系列电感器?本文将从关键参数出发,提供专业选型指导。1. 核心技术参数一览电感值范围:1nH ~ 100μH,支...
- PCIe数据包交换器核心技术解析:实现高速数据传输的关键 PCIe数据包交换器的核心作用与技术优势随着数据中心、高性能计算(HPC)和人工智能(AI)应用的快速发展,对数据传输效率的要求日益提高。PCIe数据包交换器作为连接多个设备与主机之间的核心组件,正在发挥越来越重要的作...
- 现货SMC磁性开关D-90、D-A93 D-A73:高效可靠的自动化控制选择 现货供应的SMC磁性开关D-90、D-A93和D-A73型号是工业自动化领域中不可或缺的传感设备。这些开关主要用于检测气缸活塞的位置,通过内置的磁感应元件来实现非接触式的信号传输。它们在设计上具备小巧紧凑的特点,能够轻松安装...
- 从零构建高效音讯系统:关键技术与架构设计指南 从零构建高效音讯系统:关键技术与架构设计指南构建一个高性能音讯系统并非简单地集成音频库,而是一项涉及硬件、软件、网络与人机交互的综合性工程。以下是从零开始设计音讯系统的五大关键步骤。1. 明确应用场景与需...
- 深入解读WAN2012K245H02与WAN2012H245C04数据手册中的关键设计要点 前言随着工业自动化与物联网技术的快速发展,电子元器件的选型标准日益严格。对于研发人员而言,准确理解数据手册中的各项指标至关重要。本文聚焦于WAN2012K245H02与WAN2012H245C04的数据手册内容,从可靠性、信号完整性、EMC防...
- 深度解析WAN2012K245HL5 vs H245C04:从硬件架构到实际部署的全面评测 前言:为何要进行跨型号对比?随着物联网设备日益多样化,不同型号之间的性能差异直接影响系统整体效率。本篇聚焦于两个典型代表——WAN2012K245HL5与H245C04,通过结构化对比揭示其在硬件设计、软件兼容性与现场部署中的真...
- PDC信昌协议详解:技术架构与应用场景解析 PDC信昌协议概述PDC信昌协议是一种专为工业自动化与智能设备通信设计的高效、稳定的数据传输协议。该协议由信昌科技(Xinchang Technology)自主研发,广泛应用于智能制造、物联网(IoT)、能源管理及智能楼宇等领域。核心特点...
- TSS管与聚鼎PXXXX S系列比较分析 在电力电子领域中,TSS管(Transient Voltage Suppression Tube)是一种重要的保护器件,用于防止电压瞬变对电路造成损害。聚鼎科技作为一家专注于半导体防护器件的企业,其PXXXX S系列也是市场上的热门产品之一。本文将从技术参数...
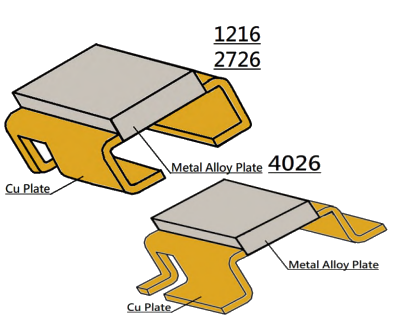
- EBR铜块分流电阻技术参数与应用分析 在电力系统和电子设备中,分流电阻器是一种重要的元件,用于测量电流强度。EBR铜块分流电阻以其高精度、低温度系数和良好的热稳定性而著称,特别适用于需要高精度电流测量的应用场合。EBR铜块分流电阻通常由高导电性材...
- 从底层通信到上层管理:深度解析 PCIe/PCI 桥接器与 PDCALPSTIA Portal PLC 的协同架构 从底层通信到上层管理:深度解析 PCIe/PCI 桥接器与 PDCALPSTIA Portal PLC 的协同架构在现代工业控制系统中,硬件底层通信能力与上层管理平台之间的无缝衔接至关重要。本文将以 PCIe/PCI 桥接器与 PDCALPSTIA Portal PLC 为核心,剖析其系...
- JMV-S积层压敏电阻详解:结构、特性与应用优势 JMV-S积层压敏电阻概述JMV-S积层压敏电阻是一种高性能的电子元件,广泛应用于电路保护领域。其核心特点是采用积层(Multilayer)结构设计,通过多层陶瓷材料与金属电极交替堆叠而成,具有优异的电压抑制能力和快速响应特性。...
- 深入解读聚鼎PXXXX S系列电感的技术优势与选型指南 聚鼎PXXXX S系列电感:专为精密电源设计打造聚鼎PXXXX S系列电感是面向高端电源管理、通信设备及工业控制系统的高性能元件。其“S”后缀代表“Superior Performance”(卓越性能),在精度、效率与尺寸小型化方面均达到行业领先水...
- 电流镜与共源共栅电流镜输出电阻的深入分析:结构与性能对比 电流镜与共源共栅电流镜输出电阻的核心差异在模拟集成电路设计中,电流镜(Current Mirror)是构建电流源、偏置电路和差分放大器的关键模块。其核心性能指标之一便是输出电阻,它直接影响电流复制的精度与稳定性。本文将重...
- HELI2 SMD-2.0X1.2mm LED灯珠参数全解析:从规格到实测数据 HELI2 SMD-2.0X1.2mm LED灯珠关键参数一览作为新一代微型LED解决方案,HELI2芯片的SMD-2.0X1.2mm封装以其紧凑结构和高性能表现备受关注。以下是其详细技术参数与实测数据对比。电气与光学参数 参数项典型值最大值 工作电压(Vf)3.2V...
- WAN2012H245C04与WAN2012F245H04数据手册深度解析:关键参数与应用指南 WAN2012H245C04与WAN2012F245H04数据手册核心概览WAN2012H245C04与WAN2012F245H04是两款广泛应用于工业控制、自动化系统及智能电网设备中的高性能电子元件。它们均属于同一产品系列,具备高度兼容性与可替代性,适用于多种复杂环境下的稳...
- WAN7020LD25N04与WAN7020L245M04数据手册深度解析:关键参数与应用场景 引言WAN7020LD25N04 和 WAN7020L245M04 是两款广泛应用于工业控制、通信设备及电源管理领域的高性能集成电路。本文将基于其官方数据手册,深入分析这两款器件的核心特性、电气参数、封装形式以及典型应用,帮助工程师快速理解并...
- WAN2012F245C04与WAN1608H245H04性能参数深度解析:高效稳定的数据传输解决方案 引言在现代工业自动化与通信系统中,高性能的通信模块是保障数据稳定传输的关键。WAN2012F245C04与WAN1608H245H04作为两款广泛应用的工业级通信设备,凭借其卓越的性能和可靠性,受到众多企业的青睐。本文将从多个维度对这两款...
- TSS管与聚鼎PXXXX T/S电感参数详解:选型指南与应用解析 TSS管与聚鼎PXXXX T/S电感参数深度解析在现代电子设备中,TSS管(Transient Suppressor Semiconductor)和聚鼎(Jude)系列电感元件是保障电路稳定性和抗干扰能力的关键组件。本文将围绕“TSS管”、“聚鼎PXXXX T”与“聚鼎PXXXX S”电感的参...